
A GPU-k fejlesztése szempontjából az MCM dizájn, vagyis az egy tokozáson belüli több lapka összeköttetése mindig is egy felszínen tartott téma volt, de az állandó kutatásokból sosem lett semmi. Pedig maga az MCM megoldás nem rossz, gondolhatunk itt arra, hogy a processzorok szempontjából többször is alkalmazta az Intel és az AMD. A működés tekintetében nem is volt probléma, feltéve ha az összeköttetésért felelős busz elegendő sávszélességet biztosított. Még nagyon távolra sem kell evezni a mai processzorok tekintetében, hiszen például az AMD EPYC termékcsaládja is MCM dizájnt használ.
Az MCM előnyei vitathatatlanok. Egy ilyen rendszer sokkal kedvezőbb gyárthatóságot biztosít egy nagy monolitikus lapkához viszonyítva, hiszen a kisebb lapkák kihozatala biztosan jobb lesz, emellett, ha a tokozáson belül marad az összeköttetés, akkor igazából lényegi hátránya nincs is. Bár az összeköttetésre szolgáló busz némi energiát igényel, de ezt bőven be lehet hozni magukon a lapkákon, mivel kisebb chipek összetokozása esetén valamivel jobb lehet az energiahatékonyság is a nagy monolitikus dizájnhoz viszonyítva.
A fentiek mellett az MCM-dizájnnal olyan skálázhatóság is elérhető, ami szimpla monolitikus lapkával gyakorlatilag lehetetlen. Bár elméletben egy nagy lapka is képes lehet ugyanarra, amire mondjuk négy kisebb, de a gyakorlatban olyan korlátokat szülnek a fizika törvényei, hogy egy bizonyos kiterjedésnél nagyobb chip nem vihető normális kihozatal mellett tömeggyártásba. Ezen a ponton kerül előnybe az MCM dizájn, ahol egy lapka megfelelően kicsire tervezhető, és még négyet egymás mellé pakolva is több feldolgozó lehet összességében a fejlesztésben, mintha egy nagy monolitikus megoldás készülne. Az egyetlen igazi hátrány csak az, hogy meg kell tervezni az MCM dizájnokhoz a működéshez szükséges interfészeket, ami tény, hogy nem egyszerű, de ha megnézzük a gyártók fejlesztéseit, ezek lényegében már léteznek is.
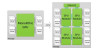
A gyártókra rátérve az NVIDIA nemrég publikált egy tanulmányt az MCM-GPU-król, ami tulajdonképpen az MCM dizájn értékelése szempontjából újat nem hoz, csupán több korábbi tanulmány által leírtakat tekinti alkalmazhatónak a GPU-kra nézve, ami aligha volt kérdés. Ebből a szempontból az a lényeges, hogy az NVIDIA kutatja ezt az irányt, és az AMD is így tesz. Korábban már volt rá utalás, hogy a Navi család a skálázhatóságot több lapka egy tokozáson belüli elhelyezésével fogja biztosítani.

Ezek a célok alapvetően átalakíthatják a GPU-kra vonatkozó tervezést, hiszen egy generáción belül jóval kevesebb lapkát kellene készíteni. Ráadásul a szükséges alapok tekintetében is jól áll mind a két cég. Az NVIDIA és az AMD is rendelkezik egy megfelelő belső fabric-kal, amit utóbbi cég Infinity Fabric néven emleget, míg az NVIDIA például sehogy, de a GV100-as GPU-ban már egy újabb fejlesztésű, névtelen fabric található.
A külső interfészek tekintetében is megoldottnak tekinthető a helyzet. Az AMD a GPU-kat a GMI-vel (Global Memory Interconnect), míg az NVIDIA az NVLINK-kel tudná összekötni. Persze itt gyors terjedést azért annak ellenére se várjunk, hogy a hardveres oldalon majdnem kész a konstrukció, előbb valószínűleg egy komoly tesztelés előzi meg a tényleges bevezetést.
Amiről igazából kevés szó esik az MCM-es GPU-k kapcsán, hogy nem csak GPU-k köthetők össze így. Ezt minden bizonnyal titkolja az AMD és az NVIDIA is, de ha csak egy picit is továbbgondoljuk a lehetőségeket, akkor bőven opció a GPU-k és a CPU-k egy tokozáson belüli összeköttetése. Ez sokkal nagyobbat fog durranni a fenti iránynál, ugyanis az AMD és az NVIDIA nagyon közel tudja helyezni a host processzorhoz a GPU-t, konkrétan annyira, hogy teljesen reálissá válik a rendszermemória közvetlen elérése a GMI és az NVLINK interfészeken keresztül. Ráadásul mind tudjuk, hogy például az AMD Vega és az NVIDIA Volta architektúra milyen fejlesztéseket tartalmaz, gondolva itt arra, hogy mindkét rendszer közvetlenül képes elérni a processzor laptábláját. Végeredményben maga a GPU a rendszer szerves részévé válhat, mindazoknak a hátrányoknak az elszenvedése nélkül, amire ma kényszeríti a PCI Express összeköttetés, vagy a modernebb memóriakoherens interfészek mellett a fizikai távolságból adódó relatíve magas késleltetés. Ez is egy kritikus fejlesztési szempont lehet az MCM dizájnok felé való közelítéskor.
A skálázhatóság javítása egyébként elsődlegesen a HPC-piac szempontjából fontos. Itt hasonló lehet a helyzet, ami ma is látszik a processzoroknál. Például az AMD csak az EPYC modellekre rak négy lapkát, míg az asztali megoldásoknál a csúcskategóriát is csak két lapkáig skálázza. Nem lenne nagy meglepetés, ha ugyanez történne meg a GPU-k területén is. Hasonlóan a HPC-piacra fókuszálhat a CPU és a GPU összetokozása. Ebből a szempontból az AMD magára számíthat, hiszen terveznek saját x86/AMD64-es processzort, amibe csak a megfelelő összeköttetéseket kell beletervezni. Az NVIDIA jelenleg az IBM Power9-cel képzeli el ezt a jövőképet, akár saját, akár partnerek által tervezett processzorral.
A tényleges elérhetőségig még nagyon sok víz le fog folyni a Dunán, de 2019-ben már okosabbak lehetünk legalább a konkrét tervek tekintetében.















