
Az AMD hivatalosan is bejelentette az újgenerációs Radeon sorozatot, mely a 7000-es számot viseli majd az RX jelölés mögött. Első körben persze a csúcsmodellek érkeznek, és ezek az új RDNA 3 architektúrát használják, ami főleg az energiahatékonyság területén villant az amúgy is takarékos elődhöz képest – ebben persze nagy segítség, hogy az új, Navi 31 kódnevű dizájn már a TSMC 5 és 6 nanométeres node-jára épül. Ez nem elírás, valójában a pirosak két gyártástechnológiát használnak, ugyanis az iparágon belül elsőként a GPU-kra is bevezetik a processzoroknál már bizonyított chiplet kialakítást.
A grafikus vezérlők esetében a vállalat pont fordítva járt el, mint a központi egységeknél, amíg ugyanis a Ryzeneken a CPU chipleteket helyezik egy I/O lapka köré, addig a GPU-knál úgynevezett MCD-ket (Memory Cache Die) raknak az egy szem GCD (Graphics Compute Die), azaz tulajdonképpen a GPU chiplet mellé. A Navi 31 kódnevű, 300 mm²-es kiterjedésű GCD készül a TSMC 5 nanométeres eljárásán, mellette pedig hat darab, egyenként 37 mm²-es, 6 nanométeres node-on gyártott MCD sorakozik. A cég szerint az összesített tranzisztorszám 58 milliárd, de nem fejtették ki külön, hogy ebből mennyit használ csak a GCD és az MCD.


 [+]
[+]
A chipletek összeköttetését a második generációs Infinity Cache-sel kiegészített Infinity Fabric végzi, méghozzá összesítve 5,3 TB/s-os adatátviteli teljesítménnyel, és ezzel a jelenlegi leggyorsabb fabric interfésznek számít. Maguk az MCD-k egyenként 64 bites memóriacsatornát, GDDR6 szabványú memóriákat támogató memóriavezérlőt, illetve egy 16 MB-os Infinity Cache szeletet tartalmaznak a GCD-vel való kommunikációhoz szükséges Infinity Fabric interfész mellett.
A koncepció itt azért nyer értelmet, mert a fizikai kiterjedést tekintve ennek a lapkának a nagy része I/O áramkörnek és gyorsítótárnak számít, amelyek nem skálázhatók túl optimálisan; emiatt érdemes 6 nanométeres node-on gyártani, mert 5 nanométeren alig lenne kisebb ugyanaz chiplet, miközben a gyártási költség a sokszorosára nőne. Ezzel gyakorlatilag az AMD megkíméli magát az utóbbi, méregdrága eljárás használatától legalább a rendszer működéséhez szükséges áramkörök egy részénél, amivel nagyon sokat nyer az előállítási költséget tekintve, amit részben nyilván eltesznek majd haszonként, részben pedig móduk nyílik a szabadabb árazásra.
Az Infinity Cache kapcsán feltűnhet, hogy csökkent a kapacitása az RDNA 2-höz viszonyítva, amit azzal magyaráznak, hogy a második generációs konstrukciónál javítottak a találati arányon – ez jó eséllyel megoldható volt, mert az első generációs Infinity Cache valójában nem volt más, mint a Zen dizájnból szimplán átemelt L3 victim cache felhizlalása, és bár a működése egyáltalán nem volt egy GPU-hoz optimalizálva, azért alapvetően hozta a kötelezőt.
A második generációs kiépítés már egy GPU működéséhez szabott gyorsítótár lett. Maradt ugyan a victim cache, de sokkal inkább igazodik ahhoz, hogy egy GPU-n belül nem csak pár, hanem nagyságrendekkel több független művelet fut, így a felépítése át lett alakítva ehhez az igénybevételhez. Emiatt már elég belőle kisebb kapacitású kiépítés is, mert jóval kevesebb lesz a cache miss.
Az AMD a GCD-n belül is módosította a rendszert, és ezen a ponton érdemes kitérni az új kijelző-, továbbá multimédiás motorra. Előbbi látványos újítása, hogy támogatja a DisplayPort 2.1-es interfészt, de valójában ehhez belül is módosult, mivel most már 54 Gbps-os sávszélességet tud kezelni, és színcsatornánként 12 bit érhető el, vagyis összességében akár 68 milliárd szín megjelenítését tudja szavatolni. A firma el is nevezte Radiance Display Engine-nek, és tényleg ez az elérhető csúcs a piacon, hiszen képes 8K-s kijelzőket 165 Hz-en meghajtani, 4K-s megjelenítőkkel pedig a 480 Hz válik elérhetővé, és a prognózis szerint az új lehetőségekre érkeznek jövőre a 2.1-es DisplayPort bemenetet használó monitorok.


 [+]
[+]
A multimédiás motor szintén továbbfejlődött, sőt, a Navi 31-ben valójában nem egy, hanem két multimédiás motorról van szó, amelyek párhuzamosan tudnak dolgozni egymással, vagyis egyszerre történhet kódolás és dekódolás HEVC, H.264, illetőleg AV1 formátumon. Utóbbi esetében elérhető lesz a másodpercenként 60 képkockát biztosító, 8K-s minőség, plusz a rendszer része lesz egy AI kódoló futószalag, ami képes javítani a felvétel vagy a stream minőségét.
Az architektúrára rátérve az AMD annyira sokat azért nem árult el róla, de az biztos, hogy az RDNA 2-höz viszonyítva elég jelentős átdolgozás történt. Egyrészt mostantól egy CU-ban, általánosabban említve multiprocesszorban másfélszer több regiszterterület található, ami főleg azért növekedett meg, mert a korábbi 32-utas SIMD tömbpár is változott. Úgynevezett dual-issue kialakítású lett a rendszer, ami azt jelenti, hogy egy shader részelemre levetítve mostantól nem csak egy, hanem két független utasítás végezhető el órajelenként. Ezt nem túl egyszerű megérteni, de a Flynn-féle osztályozási modellt figyelembe véve itt arról van szó, hogy a SIMD feldolgozó bizonyos működési módokban MIMD lett.
Ez leegyszerűsítve azt jelenti, hogy egy shader részelem a bemeneti adaton elvégezhet egy operációt, majd annak eredményén még egyet, és annak az eredményét írja ki, még ugyanabban a ciklusba. Valószínű, sőt, igazából biztos, hogy ezt a sugárkövetés miatt építették be, ugyanis a bejárással kapcsolatos feladatok egy adott operáció eredményén elég sok szorzás műveletet használnak, amit az RDNA 3 kvázi ingyen meg tud csinálni. Máshol is lehet egyébként haszna a dual-issue kialakításnak, de arra azért koncepció szintjén kell felkészíteni a kódot, tehát összességében a sugárkövetés az, ami úgy nagyjából automatikusan optimális ennek a dizájnnak. Ezen túlmenően egy CU kap két AI motort, ami szintén újítás, illetve a sugárkövetést biztosító részegység teljesítménye ugyancsak javul. Megjegyeznénk még, hogy a vörösek mostantól újra szimplán CU-ként jelzik a multiprocesszort, de ez a CU nem ugyanaz a CU, ami a korábbi RDNA dizájnokban volt, tehát a mennyiség direkt összehasonlításnak nincs értelme.
Az AMD fő célja az energiahatékonyság javítása volt, amellyel kapcsolatban 50 százalékot ígértek, és ebből végül 57 lett az RDNA 2-höz viszonyítva, mely eredményben szerepet játszik az, hogy a frekvenciák tekintetében is hozzányúltak a korábbi rendszerhez. Az elődben minden feldolgozó ugyanazon a magórajelen működött, de az RDNA 3-ban ez nem így lesz; a CU-k, vagyis a shaderek, illetve a lapka front-endje, ergo lényegében a parancsmotorok, illetve a raszterizáló és a geometriai futószalag eltérő órajelen futhat.
A működést tekintve az AMD továbbra is megad egy úgynevezett Boost órajelet, ami lényegében a beállítható maximum lesz minden részegységre. Mellé a Game órajel továbbra is azt fogja jelenteni, hogy a játékokban a CU-k tipikusan milyen frekvencián működnek, de mostantól a Boost órajelet megkaphatja minden más is. Erre elvileg azért volt szükség, mert a mai játékok tipikusan limitáltak a front-end tekintetében, így ezt a korlátozást segítenek egy picit feloldani.
A új kártyák ismert paramétereit az alábbi táblázat részletezi:
| Típus | 7900 XT | 7900 XTX |
|---|---|---|
| GPU kódneve | Navi 31 (1x GCD + 6x MCD) |
|
| Architektúra | RDNA 3 |
|
| GPU Game/Boost órajel |
2000/2400 MHz | 2300/2500 MHz |
| CU-k száma | 84 |
96 |
| Shader részelemek valós/effektív száma | 5376/10752 | 6144/12288 |
| Textúrázó csatornák száma | 336 |
384 |
| Blending egységek száma | 192 | 192 |
| Pixel kitöltési sebesség | 460,8 GPixel/s |
480 GPixel/s |
| Texel kitöltési sebesség | 806,4 GTexel/s |
960 GTexel/s |
| Elméleti számítási teljesítmény (FP32) | 52 TFLOPS | 61 TFLOPS |
| Infinity Cache | 80 MB |
96 MB |
| Infinity Cache sávszélesség | 2900 GB/s |
3500 GB/s |
| VRAM kapacitása |
20 GB |
24 GB |
| Memóriabusz | 320 bit |
384 bit |
| Effektív memória-órajel | 20 GHz |
20 GHz |
| Memória típusa | GDDR6 | |
| Memória-sávszélesség | 800 GB/s |
960 GB/s |
| TBP fogyasztás | 300 W |
355 W |
| PCI Express tápcsatlakozók | 8+8 tűs | 8+8 tűs |
| PCI Express csatoló |
x16-os PCI Express 4.0 | |

 [+]
[+]
A kimenetek tekintetében a referenciamodelleken egy HDMI 2.1, két DisplayPort 2.1, illetve egy USB Type-C lesz található, ám a Type-C-re vonatkozóan meg kell jegyezni, hogy lényeges hatása van az elméleti maximális fogyasztásra, mivel energiát is közvetíthet a csatlakoztatott eszköz felé – ez a megadott TBP értékbe bele van számolva, hiszen a VGA szempontjából teljesítményfelvétellel jár. Információink szerint nagyjából 30-40 wattról van szó mindkét SKU esetében, a port aktív használata nélküli TBP fogyasztás tehát hozzávetőleg ennyivel kevesebb.
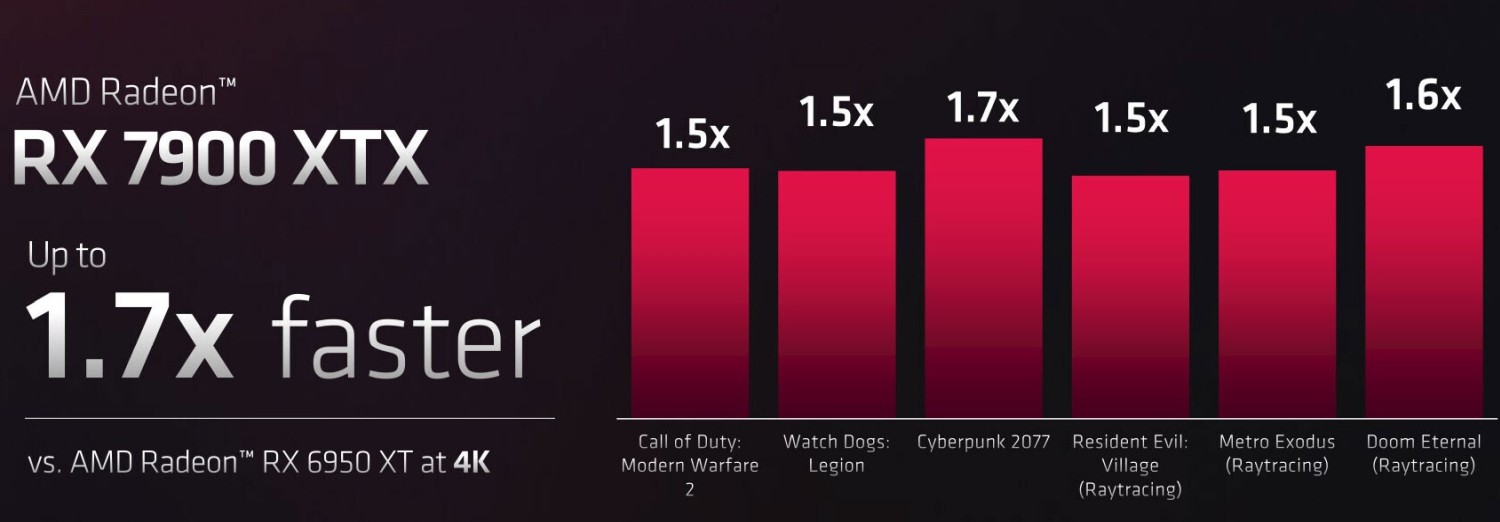
[+]
Az AMD szerint 4K-s felbontásban a Radeon RX 7900 XTX mintegy 50-70 százalékkal gyorsabb a Radeon RX 6950 XT-nél a különböző játékokban, de ennél többet egyelőre nehéz kihámozni a rendelkezésre álló adatokból. A bejelentett Radeon RX 7900 XT és 7900 XTX december 13-án érkezik rendre 900, valamint 1000 dollárért.



















